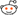
Measure LED forward voltage using Arduino
Arduino is used for many things, including testing and measuring component values.Somebody has made a resistance meter:
http://learningaboutelectronics.com/Articles/Arduino-ohmmeter.php
Another has made a capacitance meter:
https://www.arduino.cc/en/Tutorial/CapacitanceMeter
Yet another has made an inductance meter:
https://foc-electronics.com/index.php/2017/12/06/how-to-measure-inductance-with-an-arduino/
There is one missing: determine LED forward voltage.
LED comes in variety of colours, and these variations comes from different materials and different doping densities. As a result, the forward voltage of these LEDs are also not the same - lower-energy-light LEDs (e.g. red) usually require less forward voltage than higher-energy-light LEDs (white or blue). The only sure way to know is by reading its datasheet.
But what if you don't have the datasheet? Or you don't know what is the datasheet for some particular LEDs? (e.g. LEDs you salvage from some old boards).
The following Arduino circuit should help you. It helps you to figure out what is the forward voltage for an LED.
Connections
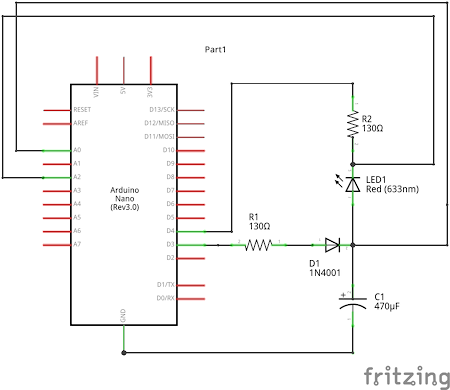
Sketch
Get the sketch.
Principle of operation
Initially we have both D3 and D4 as high (=5V). This charges the capacitor, and turns off the LED.
Then drop both D3 and D4 to low. The diode prevents the capacitor from bleeding off its charge through D3, so the only way it can discharge now is via the LED.
A0 measures the capacitor voltage.
A2 measures series resistor voltage.
A2-A0 gives you the LED voltage.
In the ideal situation, you expect to see that A0 and A2 will keep dropping off until the conduction suddenly stops, A2 becomes zero (because no more current flows through it), and then A0 will give you the LED forward voltage.
Of course, in real world this does not happen. If you test that circuit you will find that the LED will keep giving out light even when it's below its official forward voltage, and if you wait until the current is zero, the A0 voltage you get will be very much below the nominal forward voltage.
So how do we know how to stop measuring? Well, most LEDs are usually specified to be "conducting" when it pass at least 5mA of current. So when we detect the current across the resistor to be less than 5mA, we stop measuring and declare that the A2-A0 of the last measurement as the forward voltage.
Oh, how do you get the LED current? LED current is the same current that pass through its series resistor (ignoring current going out to A2). The current in the series resistor is simply its voltage (A2) divided by its resistance (130R).
Caveat
The voltage-current relation of a LED is the same as any diode - it's exponential. In other words, the forward voltage depends on the amount of current that flows (or better yet: the current that flows depend on the applied voltage). There is no single one fixed "forward voltage"; the LED will actually conduct and shine (with varying brightness) on voltages lower or higher than the official forward-voltage.
Ok, that helps. But how about forward current?
Typical LEDs uses 20mA forward current. This is regardless of the colour or the forward voltage. So there you have it. Of course, main exception for this rule is super-bright high-wattage LEDs which is meant for room illumination or for torches. These can easily pass 100mA, and some can even crank up to 500mA or more. Forward voltages on these kind of LEDs can vary a lot depending on whether you're passing 5mA or 500mA. The tester above won't work properly with these kind of LEDs.
FAQs
Q1: Why pin D3 and D4? Not D8 or D9?
A1: Because I like it that way. You can change it, but be sure to change the code too.
Q2: Why analog pins A0 and A2?
A2: Because I like it that way too. Actually, that's because an earlier design used 3 analog pins, but later on I found out that one of them (located in A1) isn't necessary, but I've already wired the circuit with A2, so it stays there. Of course you can change it, but remember to update the code too.
Q3: Why do you use 130R?
A3: 130R is the series resistor you use for LEDs with 2.4 forward voltage (green LEDs usually), which is somewhat in the middle of the range for LED forward voltages. Plus, they're what I have laying around.
Q4: Why 470uF?
A4: That's what I have laying around too. You can use other values, but make sure they're not too small.
Q5: The diode - IN4001 - you also use that because that's what you have laying around?
A5: Actually you can use any diode. In my circuit I actually used IN4007 because that's what I have laying around :)
And finally:
Q6: Why do you have separate D3 and D4? Since they will be brought HIGH and LOW at the same time, why not just use one pin?
A6: Yes, you can do it that way (remember to change the code). But using two pins make it clearer of what is happening.
Comments - Edit - Delete
Spectre on Javascript?
The chaos caused by Spectre and Meltdown seems to have quieten down. Not because the danger period is over, but well, there are other news to report. As far as I know the long tail of the fix is still on-going, and nothing short of hardware revision can really fix them without the obligatory reduction in performance.Anyway.
One of the those who quickly released a fix, was web browser vendors. And the fix was to "reduce granularity of performance timers" (in Javascript), because with high-precision timers, it is possible to do Spectre-like timing attack.
This, I don't understand. How could one perform Spectre or even Spectre-like timing attack using Javascript? Doesn't a Javascript program run in a VM? How would it be able to access its host memory by linear address, let alone by physical address? I have checked wasm too - while it does have pointers, a wasm program is basically an isolated program that lives in its own virtual memory space, no?
In other words - the fix is probably harmless, but could one actually perform Spectre or Spectre-like attack using browser-based Javascript in the first place?
That is still a great mystery to me. May be one day I will be enlightened.
Comments - Edit - Delete
Spectre and Meltdown
Forget about the old blog posts for now.Today the hot item is Spectre and Meltdown. It's a class of vulnerabilities caused by CPU bugs that allows an adversary to steal sensitive data, even without any software bugs. Nice.
Everyone and his dog is talking about it, offering their opinions and such. Thusly, I feel compelled to offer my own.
Mind you, I'm not a CPU engineer, so don't take this as infallible. In fact, I may be totally wrong about it. So treat it like how you treat any other opinions - verify and cross-check with other sources. That being said, I've done some research about it myself, so I expect that I'm not too much fooled by myself :)
Overview
There are 3 kinds of vulnerabilities: Spectre 1, Spectre 2, and Meltdown.
In very simplified terms, this is how they work:
1. Spectre 1 - using speculative execution, leak sensitive data via cache timing.
2. Spectre 2 - by poisoning branch prediction cache, makes #1 more likely to happen.
3. Meltdown - Application of Spectre 1: read kernel-mode memory from non-privileged programs.
How they work
So how exactly do they work? https://googleprojectzero.blogspot.com.au/2018/01/reading-privileged-memory-with-side.html gives you the super details of how they work, but in the nutshell, here it is:
Spectre 1 - Speculative execution is a phantom CPU operation that supposedly does not leave any trace. And if you view it from CPU point of view, it really doesn't leave any trace.
Unfortunately, that's not the case when you view it from outside the CPU. From outside, a speculative execution looks just like normal execution - peripherals can't differentiate between them; and any side effects will stay. This is well known, and CPU designers are very careful not to perform speculative executions when dealing with external world.
However, there is one peripheral that sits between CPU and external world - the RAM cache. There are multiple levels of RAM cache (L1, L2, L3), some these belongs to the CPU (as in, located in the same physical chip), some are external to the CPU. In most designs, however, the physical location doesn't matter: wherever they are, these caches aren't usually aware of differences between speculative and normal execution. And this is where the trouble is: because the RAM cache is unable to differentiate between these two, any execution (normal or speculative) will leave an imprint in the RAM cache - certain data may be loaded or removed from the cache.
Although one cannot read the contents of RAM cache directly (that would be too easy!), one can still infer information by checking whether certain set of data in inside the RAM cache or not - by timing them (if it's in the cache, data is returned fast, otherwise it's slow).
And that's how Spectre 1 works - by doing tricks to control speculative execution, one can perform an operation which normally isn't allowed to leave RAM cache imprint, which can then be checked to gain some information.
Spectre 2 - Just like memory cache and speculative execution, branch prediction is a performance-improvement technique used by CPU designers. Most branches will trigger speculative execution; branch prediction (when the prediction is correct) makes that speculation run as short as possible.
In addition, certain memory-based branch ("indirect branch") uses small, in-CPU cache to hold the location of the previous few jumps; these are the locations from which speculative execution will be started.
Now, if you can fill this branch prediction cache with bad values (="poisoning" them), you can make CPU to perform speculative execution at the wrong location. Also, by making the branch prediction errs most of the time, you make that speculative execution longer-lived than that it should be. Together, they make it more easier to launch Spectre 1 attack.
Meltdown - is an application of Spectre 1 to attempt to read data from privileged and protected kernel memory, by non-privileged program. Normally this kind of operation will not even be attempted by the CPU, but when running speculative execution, some CPU "forget" to check for privilege separation and just blindly do it what it is asked to do.
Impact
Anything that allows non-privileged programs to read and leak infomation from protected memory is bad.
Mitigation Ideas
Addressing these vulnerabilities - especially Spectre - is hard because the cause of the problem is not a single architecture or CPU bugs or anyhing like it - it is tied to the concept itself.
Speculative execution, memory cache, and branch prediction are all related. They are time-proven performance-enhancing techniques that have been employed for decades (in consumer microprocessor world, Intel was first with their Pentium CPU back in 1993 - that's 25 years ago as of this time of writing.
Spectre 1 can be stopped entirely, if speculative execution does not impact the cache (or if the actions to the cache can be un-done once speculative execution is completed). But that is a very expensive operation in terms of performance. By doing that, you more or less lose the speed gain you get from speculative execution - which means, may as well don't bother to do speculative execution in the first place.
Spectre 2 can be stopped entirely if you can enlarge the branch prediction cache so poisoning won't work. But there is a physical limit on how large the branch cache can be, before it slows down and lose its purpose as a cache.
Alternatively, it can be stopped again in its entirety, if you disable speculative execution during branching. But that's what a branch prediction is for, so if you do that, may as well drop the branch prediction too.
Meltdown however, is easier to work out. We just need to ensure that speculative execution honours the memory protection too, just like normal execution. Alternatively, we make the kernel memory totally inaccessible from non-privileged programs (not by access control, but by mapping it out altogether).
Mitigation In Practice
Spectre 1 - There is no fix available, yet (no wonder, this is the most difficult one).
There are clues that some special memory barrier instructions (i.e. LFENCE) can be modified (perhaps by microcode update?) to stop speculative execution or at least remove the RAM cache imprint by undo-ing cache loading during speculative execution, on-demand (that is, when that LFENCE instruction is executed).
However, even when it is implemented (it isn't yet at the moment), this is a piecemail fix at best. It requires patches to be applied to compilers, or more importantly any programs capable of generating code or running interpreted code from untrusted source. It does not stop the attack fully, but only makes it more difficult to carry it out.
Spectre 2 - Things is a bit rosier in this department. The fix is basically to disable speculative execution during branching. This can be done in two ways. In software, it can be used by using a technique called "retpoline" (you can google that) - which basically let speculative execution chases its own tails (=thus effectively disabling it). In hardware, this can be done by the CPU exposing controls (via microcode update) to temporarily disable speculative execution during branching; and then the software making use of that control.
Retpoline is available today. The microcode update is presumably available today for certain CPUs, and the Linux kernel patches that make use of that branch controls are also available today. However, none of them have been merged into mainline yet. (Certain vendor-specific kernel builds already have these fixes, though).
Remember, the point of Spectre 2 is to make it easier to carry out Spectre 1, so by fixing Spectre 2 it makes Spectre 1 less likely to happen to the point of making it irrelevant (hopefully).
Meltdown - This is where the good news finally is. The fix can be done, again, via CPU microcode update, or by software. Because it may take a while for that microcode update to happen (or not all), the kernel developers have come up with a software fix called KPTI - Kernel Page Table Isolation. With this fix, kernel memory is completely hidden from non-privileged programs (that's what "isolation" stands for). This works, but with a very high-cost in performance: it is reported to be 5% at minimum, and may go to 30% or more.
Affected CPUs
Everyone has a different view on this, but here is my take about it.
Spectre 1 - All out-of-order superscalar CPUs (no matter what architecture or vendor or make) from Pentium Pro era (ca 1995) onwards are susceptible.
Spectre 2 - All CPU with branch prediction that use cache (aka "dynamic branch prediction") are affected. The exact techniques to carry out Spectre 2 attack may be different from one architecture to another, but the attack concept is applicable to all CPUs of this class.
Meltdown - certain CPU get it right and honour memory protection even during specutlative execution. These CPUs don't need the above KPTI patches and they are not affected by Meltdown. Some says that CPUs from AMD are not affected by this; but with so many models involved it's difficult to be sure.
So that's it. It does not sound very uplifting, but at least you get a picture of what you're going to have for the rest of 2018. And the year has just started ...
EDIT: If you don't understand some of the terms used in this article, you may want to check this excellent article by Eben Upton.
Comments - Edit - Delete
Old blog posts
Long before time began, I had a blog. It was on a shared blogospace. I have long forgotten about it, but a few days ago I remembered about it and visited the site. To my surprise, it still exists; my old posts are still there. As if time stands still.I tried to login to that site, but Google wouldn't let me. I used Yahoo email for the login id; and I haven't accessed that email account for ages. When I tried to do that, it wouldn't recognise my password. In the light of Yahoo's massive data breach a couple years ago, this isn't surprising. I tried to recover the account using my other emails, but it didn't work either. Well, that's too bad, but I wouldn't have expected an abandoned blog to exist at all.
What I am going to do, instead, is I will scrape the text off that blog; and I will re-post some of the more interesting ones here. There are some unfinished posts there too; those whose subject I still remember I will publish the complete version here too.
Comments - Edit - Delete
How to destroy FOSS from within - Part 4
This is the fourth installment of the article.In case you missed it, these are part one and part two and part three.
I originally planned to finish this series of articles at the end of last year, so we start 2018 with a more uplifting note - but didn't have enough time so there we are. Anyway, we already start 2018 with the biggest security compromise ever (that CPU-level memory protection can be broken even without any kernel bugs, that kernel memory of any OS in the last 20 years can be read by userspace programs) - one more bad news cannot make it worse.
And now, for the conclusion.
By now you should already see how easy it is to destroy FOSS if you have money to burn.
From Part 2, we've got conclusion that "a larger project has more chance of being co-opted by someone who can throw money to get people to contribute". This is the way to co-opt the project from the bottom-up - by paying people to actively contribute and slowly redirect the project to the direction of the sponsor.
From Part 3, we've got the conclusion that "direction of the project is set by the committers, who are often selected either at the behest of the sponsor, or by the virtue of being active contributors". This is the way to co-opt the project from top-down - you plant people who will slowly rise to the rank of the committers. Or you can just become a "premium contributor" by donating money and stuff and instantly get the right to appoint a committer; and when you have them in charge, simply reject contributions that are not part of your plan. Or, if you don't care about being subtle, simply "buy off" the current committers (= employ them).
In both cases, people can revolt by forking, if they don't have the numbers, the fork will be futile because:
a) it will be short-lived
b) it will be stagnant
and in either case, people will continue to use the original project.
It's probably not the scenario you'd like to hear, but that's how things unfold in reality.
In case you think that this is all bollocks, just look around you.
Look around the most important and influential projects.
Look at their most active contributors.
Ask yourself, why are they contributing, who employs them.
Then look at the direction these people have taken. Look very very closely.
Already, a certain influential SCM system used to manage a certain popular OS, is now more comfortable to run on a foreign OS than the OS that it was originally developed (and is used to manage).
Ask yourself how can this be. "Oh, it's because we have millions of downloads of for that foreign OS, so that foreign OS is now considered as a top-tier platform and we have to support that platform" (to the extent that we treat the original OS platform as 2nd tier and avoid using native features which cannot be used on that foreign OS, because, well, millions of downloads). Guess what? The person who says that, works for the company that makes that foreign OS. And not only that, he's got the influence, because, well, there are a lot of "contributors" coming from where he works.
What's next? bash cannot use "fork()" because a foreign OS does not support fork()?
Who pays for people who works on systemd? Who pays for people to work on GNOME? Who pays for people to work on KDE? Who pays for people who works on Debian? Who are the members of Linux Foundation? You think these people work out of the kindness of their heart for the betterment of humanity? Some of them certainly do. Some, however, work for the betterment of themselves - FOSS be damned.
Comments - Edit - Delete
How to destroy FOSS from within - Part 3
This is the third installment of the article.In case you missed it, these are part one and part two.
In the previous post, I stated that the direction in an FOSS project is set by two groups of people:
a) People who work on the project, and
b) People who are allowed to work on the project.
We have examined (a) in part two, so now let's examine (b).
Who are the people allowed to work on the project? Aren't anyone allowed? The answer is a solid, resounding, "NO".
Most FOSS projects, if they are contributed by more than one person, tend to use some sort of source code management (SCM). In a typical SCM system, there are two classes of users: users with commit rights, who can modify the code in the SCM (committers), and read-only users, who can read and check-out code from the SCM but cannot change anything.
In most FOSS projects, the number of committers are much smaller than the read-only users (potentially anyone in the world with enough skill is a read-only user if the SCM system is opened to the world e.g. if you put the code in a public SCM repository e.g. github and others).
The committers don't necessarily write code themselves. Some of them do; some of them just acts are a "gatekeeper"; they receive contributions from others; vet and review the changes; and "commits" them (=update the code to the SCM) when they think that the contribution has met certain standards.
Why does it matter? Because eventually these committers are the ones that decide the direction of the project by virtue of deciding what kind of changes are accepted.
For example, I may be the smartest person in the world, I may be the most prolific programmer or artists in the world; if the committers of the project I want to contribute don't accept my changes (for whatever reason); then for all practical purposes I may as well don't exist.
Hang on you say, FOSS doesn't work this way. I can always always download the source (or clone the repo) and work it on my own! No approval from anybody is required!
Yes, you can always do that, but that's you doing the work privately. That's not what I mean. As far as the project is concerned, as far as the people who use that project is concerned; if your patches aren't committed back to the project mainline, then you're not making any changes to the project.
But hey hey, wait a minute here you say. That's not the FOSS I know. The FOSS I know works like this: If they don't let me commit this large gobs of code that I've written, what's stopping me to just publish my private work and make it public for all to see and use? In fact, some FOSS licenses even require me to do just that!
Oh, I see. You're just about to cast the most powerful mantra of all: "just.fork.it", is it?
I regret to inform you that you have been misinformed. While the mantra is indeed powerful, it unfortunately does not always work.
Allow me to explain.
Fork usually happens when people disagree with the committers on the direction they take.
Disagreement happens all the time, it's only when they are not reconcilable that fork happens.
But the important question is: what does the forking accomplish in the end?
Personally, I consider a fork to be successful if it meets one of two criteria:
a) the fork flourishes and develops into a separate project, offering alternatives to the original project.
b) the fork flourishes and the original project dies, proving that the people behind the original project has lost their sights and bet in the wrong direction.
In either case, for these to happen, we must have enough skilled people to back the fork. The larger the project, the more complex the project, the more skilled people must revolt and stand behind the fork. It's a game of numbers; if you don't have the numbers you lose. Even if you're super smart, you only have 24 hours a day so chances are you can never single-handedly fork a large-scale project.
In other words, "just.fork.it" mantra does not always work in real world; in fact, it mostly doesn't.
Let's examine a few popular works and let's see how well they do.
1. LibreOffice (fork of OpenOffice). This is a successful fork, because most of the original developers of OpenOffice switch sides to LibreOffice. The original project is dying.
2. eglibc (fork of glibc). Same story as above. Eventually, the original "glibc" folds, and the eglibc fork is officially accepted as the new "glibc" by those who owns "glibc" name.
3. DragonflyBSD (fork of FreeBSD). Both the fork and the original survives; and they grow separately to offer different solutions for the same problem.
4. Devuan (fork of Debian). The fork has existed for about two years now, the judge is still out whether it will be successful.
5. libav (fork of ffmpeg). The fork fails; only Debian supported it and it is now dying.
6. cdrkit (fork of cdrtools). The fork fails; the fork stagnates while the original continues.
7. OEM Linux kernel (fork of Linux kernel). There are a ton of these forks, each ARM CPU maker and ARM boardmaker effectively has one of them. They are mostly failed; the fork didn't advance beyond the original patching to support the OEM. That's why so may Android devices are stuck at 3.x kernels. Only one or two are successful, and those who are, are merging back their changes to the mainline - and eventually will vanish once the integration is done.
8. KDE Trinity (fork of KDE). It's not a real fork per se, but more of a continued maintenance of KDE 3.x. It fails, the project is dying.
9. MATE desktop (fork of GNOME). Same as Trinity, MATE is not a real fork per se, but a continued maintenance of GNOME 2.x. I'm not sure of the future of this fork.
10. Eudev (fork of systemd-udev). The fork survives, but I'd like to note that the fork is mostly about separating "udev" from "systemd" and is not about going to separate direction and implementing new features etc. Its long-term survivability is questionable too because only 2 people maintain it. Plus, it is only used by a few distributions (Gentoo is the primary user, but there are others too - e.g. Fatdog).
11. GraphicsMagick (fork of ImageMagick). The fork survives as an independent project but I would say it fails to achieve its purpose: it doesn't have much impact - most people only knows about ImageMagick and prefers to use it instead.
I think that's enough examples to illustrate that in most cases, your fork will only **probably** survive if you have the numbers. If you don't, then the fork will either die off, or will have no practical impact as people continue to use the original project.
In conclusion: The mantra of "just.fork.it" is not as potent as you thought it would be.
As such, the direction of the a project is mostly set by committers. Different projects have different policies on how committers are chosen; but in many projects the committers are elected based on:
a) request by the project (financial) sponsor, and/or
b) elected based on meritocracy (=read: do-ocracy) - how much contribution he/she has done before.
But remember what I said about do-ocracy?
Comments - Edit - Delete
How to destroy FOSS from within - Part 2
This is the second installment of the article. In case you missed it, part one is here.In the past, companies try to destroy FOSS by disreputing them. This is usually done by hiring an army of paid shills - people who spread hoaxes, misinformation, and self-promotion where FOSS people usually hang around (in forums, blog comments), etc. This is too obvious after a short while, so the (slightly) newer strategy is to employ "unhelpful users" who hangs around the same forum and blog comments, pretending to help, but all they do is to shoot down every question by embarassing the inquirer (giving "oh noobs questions, RTFM!", or "why would you want to **do that**???" type of responses, all the time).
Needless to say, all these don't always work (usually they don't) as long as the project is still active and its community isn't really filled with assholes.
In order to know how to destroy FOSS, we need to know how FOSS survives in the first place. If we can find lifeline of FOSS; we can choke them and FOSS will inevitably die a horrible death.
The main strength of FOSS is its principle of do-ocracy. Things will get done when somebody's got the itch do to it; and that somebody will, by virtue of do-ocracy, sets the direction of the project.
The main weakness of FOSS is its principle of do-ocracy. Things will get done when somebody's got the itch do to it; and that somebody will, by virtue of do-ocracy, sets the direction of the project.
The repeated sentence above is not a mistake, it's not a typo. Do-ocracy is indeed both the strength and the Achilles' heel of FOSS. Let's see this is the case.
Direction in an FOSS project is set by two groups of people:
a) People who work on the project, and
b) People who are allowed to work on the project.
Lets examine (a).
Who are the people who work on the project? They are:
1) People who are capable of contributing
2) People who are motivated to contribute
Let's examine (1).
Who are the people capable of contributing? Isn't everyone equally capable? The answer is, though may not be obvious due to popular "all people is equal" movement, is a big, unqualified NO. People who are capable of contributing are people who have the skill to do so. Contribution in documentation area requires skilled writers; contribution artworks require skillful artists; contribution in code requires masterful programmers. If you have no skill, you can't contribute - however motivated you are.
The larger a project grows, the more complex it becomes. The more complex it comes, the more experience and skill is needed before somebody can contribute and improve the project. To gain more skill, somebody needs to invest the time and effort; and get themselves familiar with the project and or the relevant technology. Bigger "investment" means less number of people can "afford" it.
And this creates a paradox. The more successful a project becomes, the larger it becomes. The larger it becomes, the more complex it becomes. The more complex it becomes, the smaller the available talent pool.
Let's examine (2).
People contributes to FOSS projects for many reasons, some are less noble than others. Example:
- School projects (including GSoC)
- Some does it out for "paying back" ("I used FOSS software in the past, now I'm paying it back by contributing").
- Some does it for fame and want to show off their skils.
- Some does it just to kill time.
- Some does it for enhancing their resume (oh wow - look at the number of projects in my github account !!! (although most of them are forks from others ...)).
- Some does it because they are the only one who needs the feature they want, so they just get it done.
- Etc, the reasons are too numerous to list. But there is one **BIG** motivation I haven't listed above, and I'm going to write it down in a separate sentence, because it is worthy of your attention.
👉👉👉 Some does it because it is their day job; they are being paid to do so 👈👈👈
What can we conclude from (1) and (2)?
A larger, more complex project requires people with more skills.
More skills requires more investment.
More investment requires more motivation.
Motivation can be bought (=jobs).
Thus it leads to the inevitable that: the more complex a project becomes, the more chance that the people who are working on it are paid employees. And paid employees follows the direction of their employer.
In other words: a larger project has more chance of being co-opted by someone who can throw money to get people to contribute.
We will examine (b) in the next installment.
Comments - Edit - Delete
xscreenshot is updated
xscreenshot, my dead simple screen capture program for X11, gets a facelift. It can now capture screenshot with mouse cursors in it; and it can also capture a single window. Oh, and now the filenames are created based on timestamp, rather than just a running number. You can get the latest version from here.Comments - Edit - Delete
How to destroy FOSS from within - Part I
Although I don't set the scope of this blog, from my previous posts it should be obvious that this is a technical blog. I rarely post anything which is non-technical in nature, here; and I plan to keep it that way.But there have been things moving under the radar which, while in itself is not technical in nature, will affect technical people the most, and hit them the hardest. Especially people working in the FOSS, either professionally, or as hobby.
The blog post is too long to write in one go, so I will split this into a few posts.
For many years, I have been under the silly belief that nothing, nothing, short of global-level calamity (the kind that involves extinction of mankind), can stop the FOSS movement. The horse has left the barn; the critical mass has been reached and the reaction cannot be stopped.
The traditional way companies have fought each other is by throwing money for marketing and fire sale; outspending each other until the other cave in and goes bankrupt. Alternatively, they can swallow each other ("merge and acquire"); and once merged they just kill the "business line" or "the brand".
But they can't fight FOSS like that. Most FOSS companies survive on support. You can acquire them (e.g. MySQL), and then kill them; but one can easily spring up the next day (e.g. MariaDB). You cannot use fire sale on software licensing continuously, because the price of FOSS software licensing is eventually $0, and you can't compete with "free", well, not forever.
I still remember the days that a certain proprietary software company threw their flailing arms up in the air in exasperation, for not being able to compete against FOSS. The only thing they could do was bad-mouth FOSS and keep talking about "quality", and "amateur", and "unprofessional" when it was obvious their own products and conducts was none the better either.
So I was a believer that money cannot stop FOSS.
And how wrong I turned out to be.
Comments - Edit - Delete
Booting your BIOS system via UEFI
In my previous post, I wrote about my exploration on running UEFI on BIOS based systems. The original motivation was to find "cure" to long boot time from USB flash drive, when initrd is large (like the case in Fatdog). I reasoned that since in many BIOS systems USB booting is done via hard-disk emulation (and thus it depends on the quality of the emulation), it would be better to run a firmware that recognises and is capable of booting from USB devices directly, without emulation.I managed to get DUET working on qemu, but it didn't work on some of my target systems. Another alternative that I explored is CloverEFI, which is a fork of DUET. This worked better than DUET and it booted on systems where DUET wouldn't. However, I could not notice improvement on boot times. I haven't looked at DUET disk driver; I was hoping that it would provide a hardware UHCI/EHCI driver but probably doesn't - if it still depends on BIOS to access the USB via hard-disk emulation, then I've gained nothing.
So the initial objective can be considered as a failure.
However, come to think of it, I now have a better reason why you want to run UEFI on your BIOS system. When you run DUET, you are, essentially, "flashing" your BIOS and "upgrading" it with a newer UEFI firmware. While BIOS can do most of what UEFI can, there is one thing that it cannot do: it cannot boot from disk over 2TB in size†. This is not a hardware limitation, it is a consequence of applying a 36-year old design meant for 5 MB harddisk to today's world. With UEFI "update", you can format your disk using GPT and boots successfully from it.
Note†: It is possible to format the disk using GPT and have BIOS boots from it. I even described the process on my own article. That article, however, has a non-obvious limitation: the bootloader you use, must be capable of using the filesystem and booting the OS of your choice. The article was targeted for Linux users, thus syslinux was the chosen example and it would work beautifully. If, however, you want to boot other OS that syslinux doesn't understand, then you have to choose a different boot loader that:
a) can be booted by BIOS
b) understands GPT
c) can boot your OS of choice
In this case, booting GPT disk via DUET doesn't sound very unreasonable, considering that you've got more choice of UEFI bootloaders than non-UEFI ones for some specific OS.
Comments - Edit - Delete

